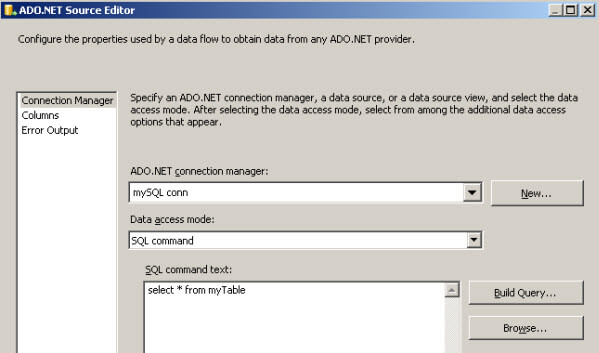
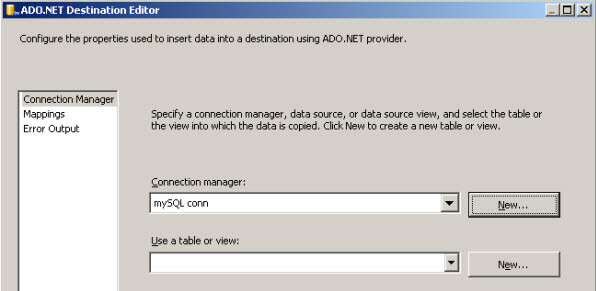
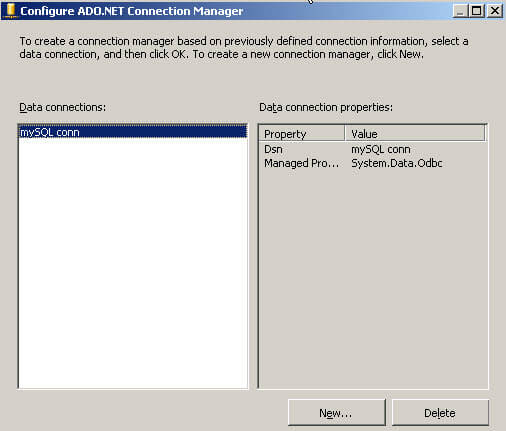
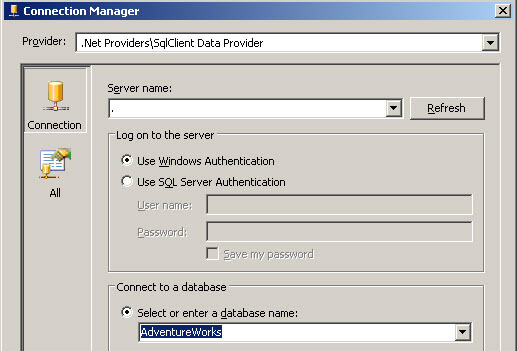
Problem
Sometimes we need to compare tables and/or data to know what was changed. This tip shows you different ways to compare data, datatypes and tables.
Solution
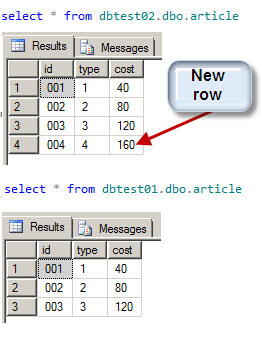
I will show you different methods to identify changes. Let's say that we have two similar tables in different databases and we want to know what is different:
The T-SQL code generates 2 tables in different databases. The table names are the same, but the table in database dbtest02 contains an extra row:
Let's look at ways we can compare these tables using different methods.
Compare Tables Using a LEFT JOIN
With the left join we can compare values of specific columns that are not common between two tables.
For example:
select *
from dbtest02.dbo.article d2
left join dbtest01.dbo.article d1 on d2.id=d1.id
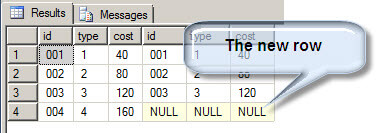
The left join shows all rows from the left table "dbtest02.dbo.article", even if there are no matches in the "dbtest01.dbo.article":
In this example, we are comparing 2 tables and the values of NULL are displayed if there are no matching rows. This method works to verify new rows, but if we update other columns, the left join does not help. Is there another method to compare tables? Let's use the Except clause to see what we can find.
Compare Tables Using the EXCEPT Clause
The Except method shows the difference between two tables (the Oracle guys use minus instead of except and the syntax and use is the same). It is used to compare the differences between two tables. For example, let's see the differences between the two tables:
Now let's run a query using except:
select * from dbtest02.dbo.article
except
select * from dbtest01.dbo.article
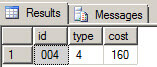
The except returns the difference between the tables from dbtest02 and dbtest01:
If we flip the tables around in the query we won't see any records, because the table in database dbtest02 has all of the records plus one extra.
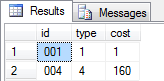
This method is better than the first one, because if we change values for other columns like the type and cost, the except will notice the difference. Here is an example if we update id "001" in database dbtest01 and change the cost from "40" to "1". If we update the records and then run the query again we will see these differentness now:
Unfortunately it does not create a script to synchronize the tables. Is there a way to compare tables and synchronize results?
Compare Tables Using the Tablediff Tool
There is a nice command line tool used to compare tables. This can be found in "C:\Program Files\Microsoft SQL Server\110\COM\" folder. This command line tool is used to compare tables. It also generates a script with the insert, update and delete statements to synchronize the tables. For more details, refer to this
tablediff article.
Compare Changes in a Table Using the Change Data Capture CDC
This feature was added in SQL Server 2008. You need to enable this feature and you also need to have SQL Server Agent running. Basically it creates system tables that track the changes in your tables that you want to monitor. It does not compare tables, but it tracks the changes in tables.
Compare Data Types Between Two Tables
What happen if we want to compare the data types? Is there a way to compare the datatypes?
Yes, we can use the [INFORMATION_SCHEMA].[COLUMNS] system views to verify and compare the information. We are going to create a new table named dbo.article2 with a column with different data type than the dbo.article table:
USE dbtest01
GO
CREATE TABLE [dbo].[article2](
[id] [int] NOT NULL,
[type] nchar(10) NULL,
[cost] nchar(10) NULL,
CONSTRAINT [PK_article1] PRIMARY KEY CLUSTERED
(
[id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
The difference is that the id is now an int instead of nchar(10) like our other tables.
The query to compare data types of the article and article 1 would be:
USE dbtest01
GO
select c1.table_name,c1.COLUMN_NAME,c1.DATA_TYPE,c2.table_name,c2.DATA_TYPE,
c2.COLUMN_NAME
from [INFORMATION_SCHEMA].[COLUMNS] c1
left join [INFORMATION_SCHEMA].[COLUMNS] c2 on c1.COLUMN_NAME=c2.COLUMN_NAME
where c1.TABLE_NAME='article'
and c2.TABLE_NAME='article2'
and c1.data_type<>c2.DATA_TYPE
The results are as follows:
The query compares the data types from these two tables. All the information of the columns can be obtained from the [INFORMATION_SCHEMA].[COLUMNS] system view. We are comparing the table "article" with the table "article2" and showing if any of the datatypes are different.
Compare if there are Extra Columns Between Tables
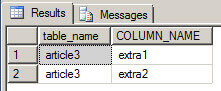
Sometimes we need to make sure that two tables contain the same number of columns. To illustrate this we are going to create a table named "article3" with 2 extra columns named extra1 and extra2:
USE dbtest01
GO
CREATE TABLE [dbo].[article3](
[id] [int] NOT NULL,
[type] nchar(10) NULL,
[cost] nchar(10) NULL,
extra1 int,
extra2 int
)
In order to compare the columns I will use this query:
USE dbtest01
GO
select c2.table_name,c2.COLUMN_NAME
from [INFORMATION_SCHEMA].[COLUMNS] c2
where table_name='article3'
and c2.COLUMN_NAME not in (select column_name
from [INFORMATION_SCHEMA].[COLUMNS]
where table_name='article')
The query compares the different columns between table "article" and "article3". The different columns are extra1 and extra2. This is the result of the query:
Compare Tables in Different Databases
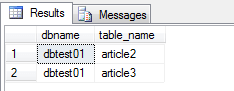
Now let's compare the tables in database dbtest01 and dbtest02. The following query will show the different tables in dbtest01 compared with dbtest02:
select 'dbtest01' as dbname, t1.table_name
from dbtest01.[INFORMATION_SCHEMA].[tables] t1
where table_name not in (select t2.table_name
from
dbtest02.[INFORMATION_SCHEMA].[tables] t2
)
union
select 'dbtest02' as dbname, t1.table_name
from dbtest02.[INFORMATION_SCHEMA].[tables] t1
where table_name not in (select t2.table_name
from
dbtest01.[INFORMATION_SCHEMA].[tables] t2
)
Third Party Tools
ref:http://www.mssqltips.com/sqlservertip/2779/ways-to-compare-and-find-differences-for-sql-server-tables-and-data/?utm_source=dailynewsletter&utm_medium=email&utm_content=headline&utm_campaign=20140124